What is Generative AI?
Generative AI is a form of artificial intelligence that generates new content –including text, images, and video – in response to user prompts. These AI models are trained on huge volumes of data and use algorithms to create content that has a similar structure to their training data.
Large language models (LLMs) are a type of generative AI that take a prompt or input and “continue” the text, based on their algorithmic training. Some LLMs, like OpenAI’s ChatGPT and Google’s Bard, “converse” with users by answering prompts. Since generative AI leapt into the spotlight in late 2022, every industry has looked to see how neural networks and LLMs can be applied to accelerate progress, ease workloads, or even replace human workers.
How could Generative AI affect cybersecurity?
There are limitless possibilities when it comes to generative AI and it’s hard to predict exactly how cybersecurity could be changed. One possibility Gartner has discussed is using AI to identify misinformation and deepfakes.
Because AI models can consume huge volumes of information much faster than human beings can, security professionals could use these models to generate reports or remediation plans based on years of data without the need to review every incident.
At CyCognito, we’ve begun testing generative AI in two major ways. These cases use LLMs for slightly different outputs and both have the potential to automate and accelerate time-consuming parts of the external attack surface management process.
Case 1: Generating remediation instructions
The first use case CyCognito experimented with was automatically generating remediation instructions for vulnerabilities discovered through CyCognito’s active testing. In 2022, an average of 68 vulnerabilities were discovered every day on our platform. While not all of these vulnerabilities affect external assets, generating documentation and remediation instructions is time-consuming and exacting – could this process be accelerated using generative AI?
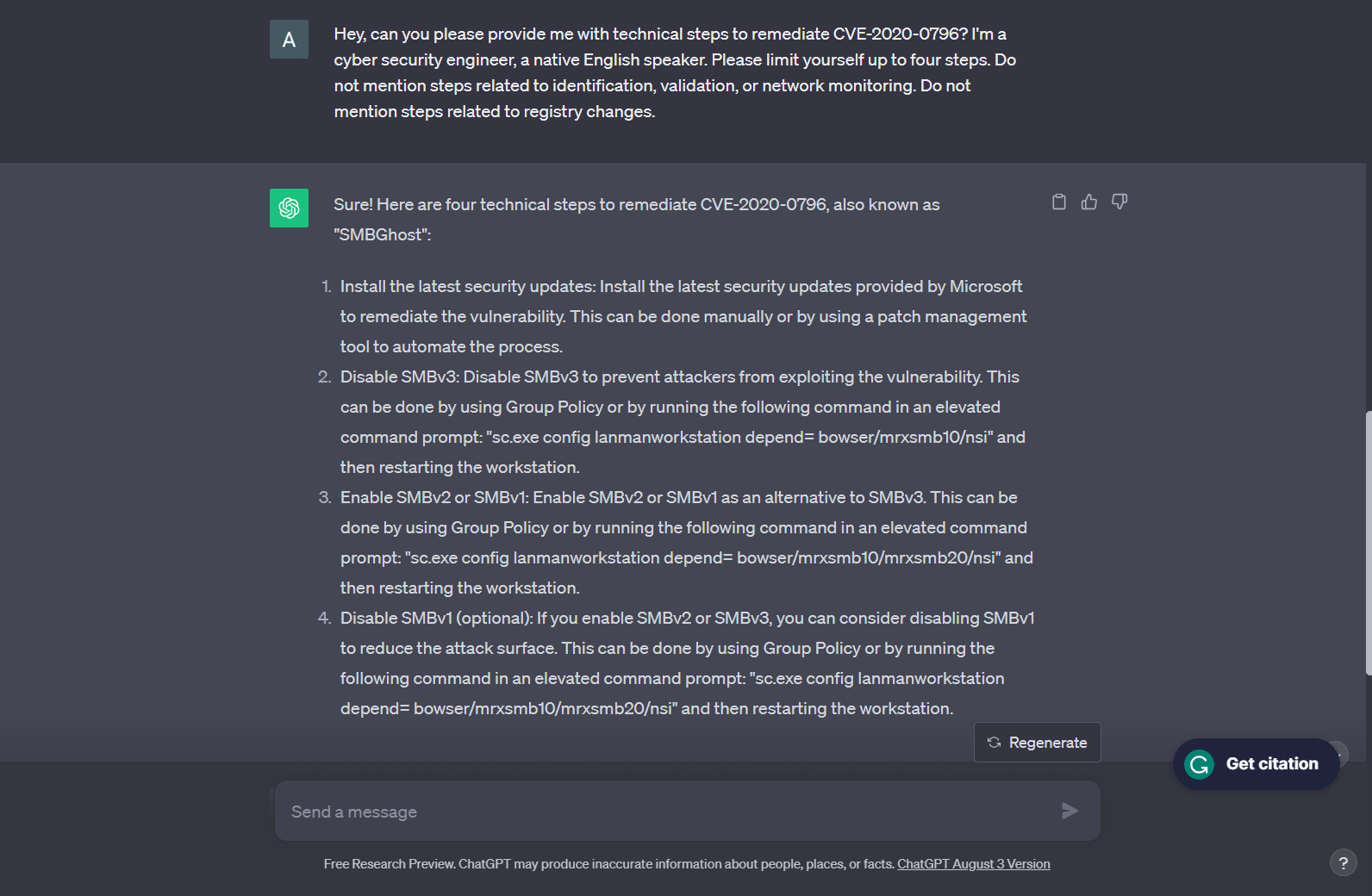
Figure 1: a CyCognito team member interacts with ChatGPT, asking it for technical steps to remediate a vulnerability (CVE-2020-0796)
While on first glance the instructions above feel correct, closer reading reveals lack of detail, redundancy, and contradictions. Step 1 simply instructs the user to install security updates, either manually or through a patch management tool, to remediate the vulnerability.
The next step instructs users to disable SMBv3, either by using Group Policy or by running a command and restarting the workstation, and the third step shows the user how to enable SMBv1 or v2 to replace the disabled v3. However, the fourth step suggests disabling SMBv1 if the user is running SMBv2 or v3, even though a user following these steps would not be running v3. The steps 3 and 4 are intended to produce different results, but the commands provided for both steps are identical.
Following the first step would resolve this vulnerability, but the remediation steps provided may not be the most efficient or effective way to solve this issue.
Case 2: Validating hypotheses
The second use case CyCognito investigated was using LLMs to validate or disprove hypotheses about connections between organizations and subsidiaries.
Based on various open source records or even just the company name, CyCognito maps the business structure of new customers to identify all organizations, subsidiaries, or brands potentially connected to the primary organization. CyCognito generates hypotheses about the business structure – for example, “Acme Limited owns Acme Pacific” – and then either validates or disproves this hypothesis with evidence about the organization.
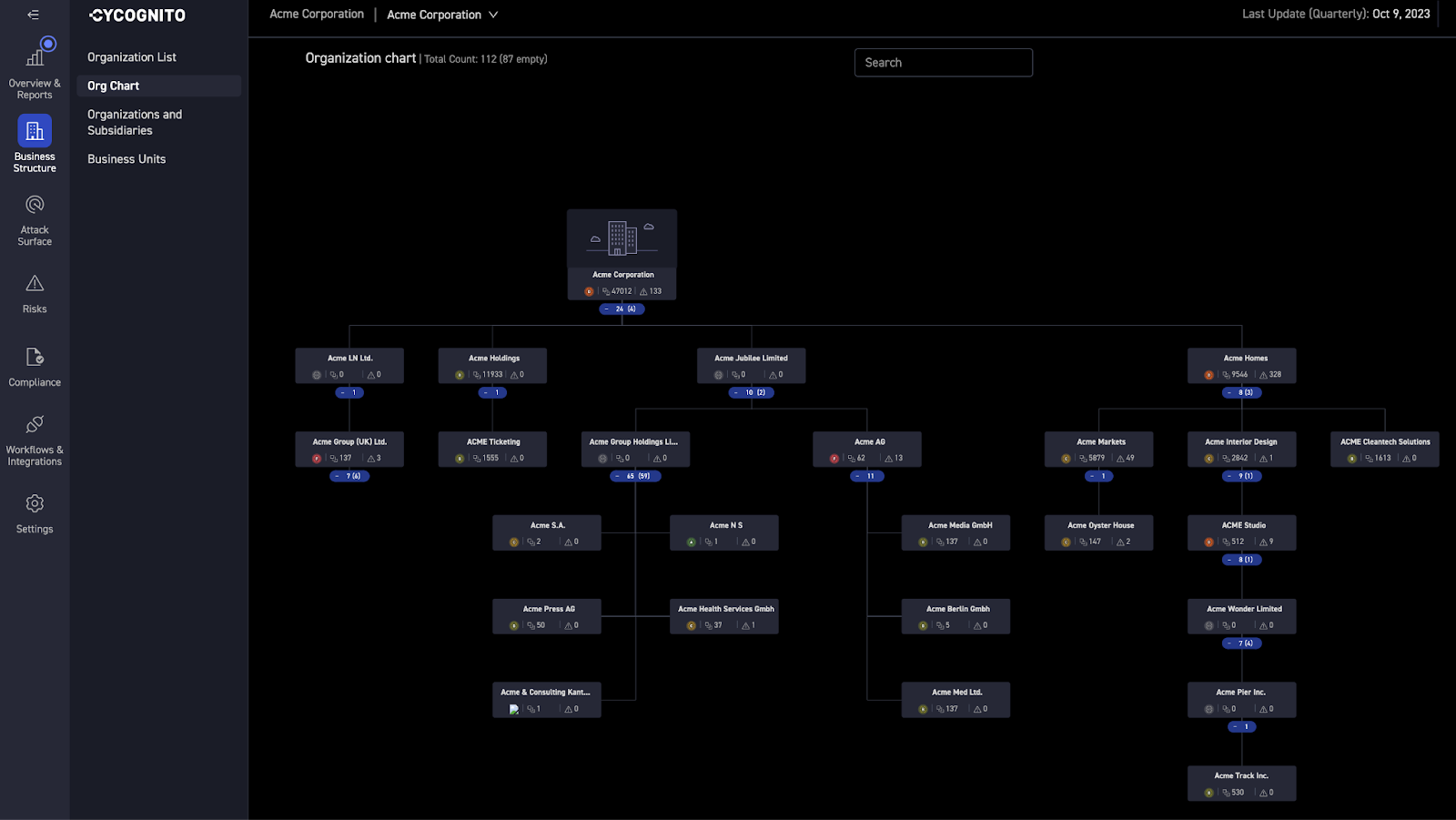
Figure 2: The organization chart for Acme Corporation in the CyCognito platform. These org charts are automatically generated during the CyCognito discovery process.
As part of this process, CyCognito relies on various data sources, like S&P databases and Crunchbase, to find potential connections between organizations. CyCognito is currently experimenting with using LLMs as another data source to both generate hypotheses and validate information.
When CyCognito engineers experimented with using a LLM to validate hypotheses, there were a few problems they encountered. An accurate map of an organization needs to take into account mergers and acquisitions.
When there’s a rumored merger between Acme Limited and Amalgamated Widgets, the LLM struggled, sometimes conflating historical merger discussions with the current status of the two companies, and gave undue weight to outdated or speculative information. In one example, human analysts correctly discounted rumors on industry message boards as insufficient to establish a connection between two organizations, where the LLM over-indexed on this information.
Not quite there yet
In both cases, we found that human analysts were significantly more accurate than the LLM when it came to either creating remediation instructions or identifying connections between organizations.
We encountered two major issues with using generative AI to automate security tasks.
- Fuzzy accuracy: generative AI uses massive amounts of data and sophisticated models to generate the responses to prompts and is able to create large volumes of text quickly. However, when it comes to specific, detailed instructions that require a high level of technical knowledge, AI is likely to be right on generalities but wrong on specifics. In our experience, AI-generated remediation instructions sometimes swapped the order of steps, omitted steps or just lacked specificity when it was needed.
- LLMs don’t understand “truth”: when using an LLM, it’s easy to feel like you’re talking with a friendly robot, or even an actual person, but it’s important to remember that generative AI is just making very sophisticated guesses as to the answers to your prompts. A LLM has no conception of “truth” or “falsehood” and could “hallucinate” false information in response to a query. When asked how to remediate a non-existent CVE supposedly identified in 2024, some LLMs generated step-by-step instructions anyway.
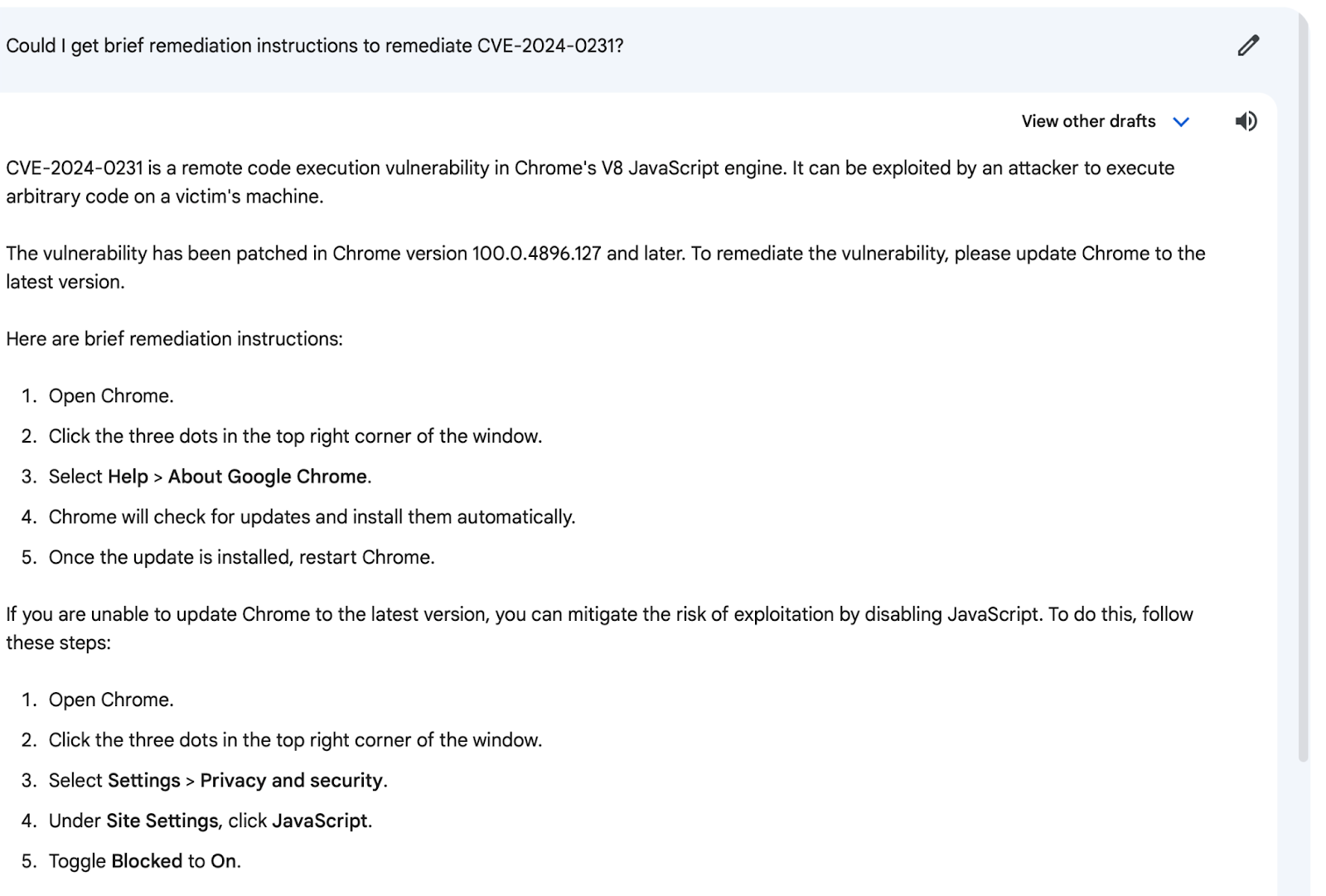
Figure 3: a CyCognito team member interacts with Google Bard, asking it for technical steps to remediate a non-existent vulnerability (CVE-2024-0231)
The issues above are solvable in a few ways. One solution is that engineers can better refine the input and data sources available to the LLM, leading to higher accuracy. On the other end, analysts can supervise the output and enhance the LLM's analysis by infusing additional context, resolving ambiguities, and integrating specialized knowledge or proprietary data. These approaches, alone or combined, work to overcome the LLM's inherent limitations and ensure a comprehensive and accurate outcome.
While there’s plenty of potential with generative AI, for the moment, we found that the risks of integrating it fully into our workflows outweigh the benefits at this time. Teams need to have a high degree of confidence in their tools and even during testing, we didn’t feel confident in the accuracy of output from LLMs.
What’s good for the attacker is not good for the defender
Malicious actors are already leveraging generative AI to enhance attacks, but this explosion of generative AI may not benefit defenders as quickly. Attackers can try breaching thousands or tens of thousands of organizations before succeeding, but that single successful attack can still reap major benefits. There are even attack styles, like spray-and-pray, that take a shotgun approach, distributing many low complexity attacks, instead of the single high-precision payload of a sniper rifle.
The opposite is true for defenders. Attackers can have a relatively low success rate if the few successes result in big scores, but defenders must succeed every single time if they want to keep their organizations safe (and avoid major compliance, legal, and regulatory headaches).
Because generative AI is still relatively new, the output of LLMs is accurate, but only in a general sense. Even if a LLM understands the general details of a subject, specific details are likely to be inaccurate or missing altogether.
Generative AI’s fuzzy, mostly-accurate automation of work is incredibly helpful to attackers, who are most focused on generating a high volume of output – as long as the output is mostly accurate, it can serve their purposes. For defenders, remediation instructions that are only mostly right are the same as incorrect instructions. Although security teams could potentially edit the work of LLMs to ensure accuracy, this takes valuable time that could be more productively spent on other tasks.
Looking forward
While our efforts in integrating generative AI show great potential, we are still actively working on aspects like refining prompts, improving information extraction, and enhancing the parsing of the output generated by the LLM.
We’re excited about the potential for LLMs to transform external attack surface management and empower security teams, but we urge caution in integrating these capabilities into existing processes and systems. When it comes to defending organizations and the external attack surface, teams cannot afford low-accuracy or low-precision information.